KubeFlow-机器学习平台
KubeFlow介绍
KubeFlow是一个开源项目,目标是让在k8s上部署、管理和运行机器学习应用更加简单。
以下是KubeFlow的架构:
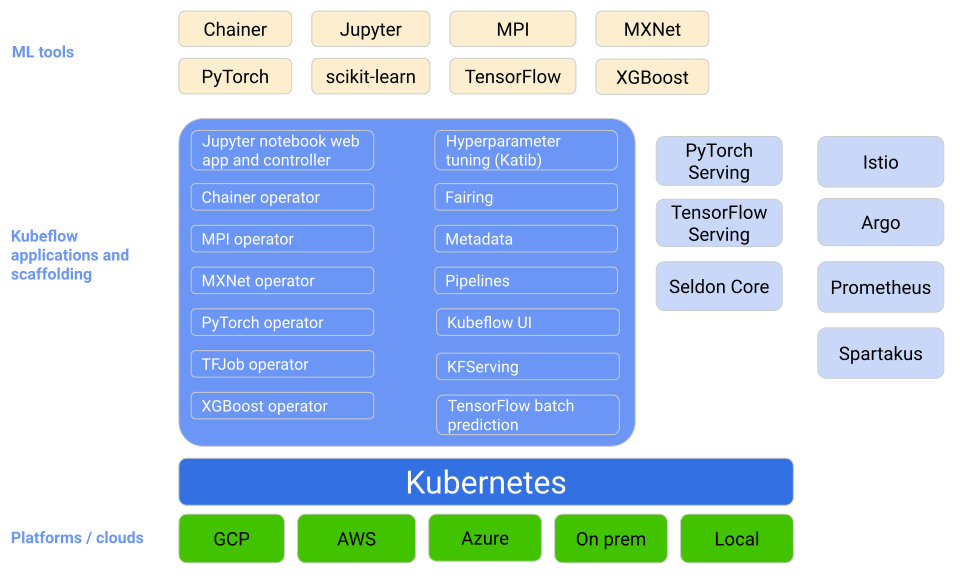
可以看到,KubeFlow并不只是一个工具,而是一系列工具的集合,是一个平台。
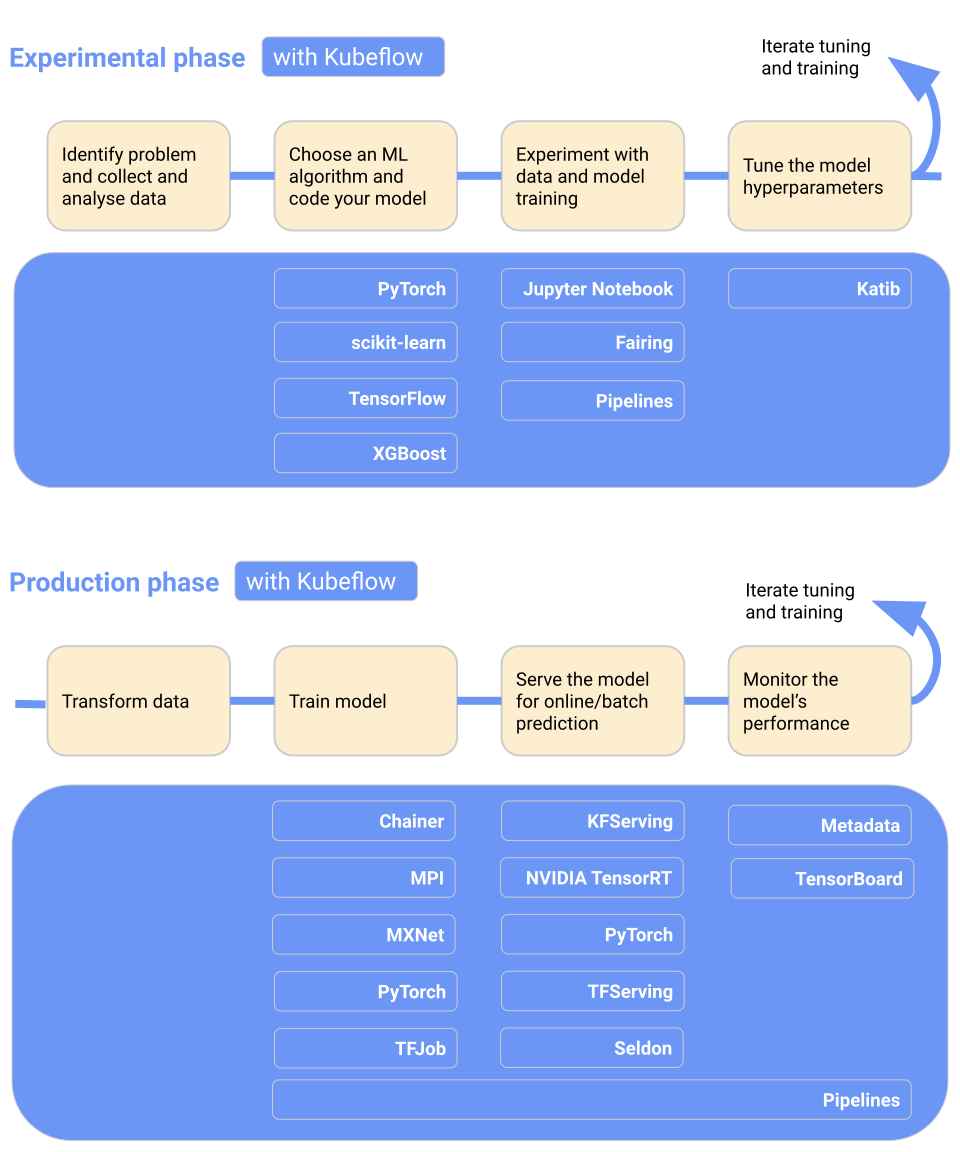
KubeFlow的架构跟机器学习工作流是息息相关的:
- 在实验阶段,KubeFlow提供了jupyter notebook工具帮助机器学习工程师开发模型
- 在生产阶段,KubeFlow提供了TFJob、PyTorchJob工具进行大规模分布式训练,同时也提供了KServe工具部署推理服务
KubeFlow是什么:
- 一组机器学习工具集,可以理解为一个技术栈
- 一种解决方案,帮助在k8s上开发、部署机器学习应用
KubeFlow不是什么:
- 不是机器学习框架,跟TensorFlow、PyTorch不是一类东西
- 不是资源管理平台,依赖k8s来完成调度,但是kubeflow会根据机器学习应用的特征调整k8s的调度策略,比如gang scheduling
关键组件分析
KubeFlow包含了一大堆工具集,这里只从开发、训练和推理3个阶段,每个阶段挑选1个关键组件进行分析。
模型开发 - Notebook

Jupyter Notebook是一个基于浏览器的交互式开发环境,做过机器学习的同学应该都用过, 非常好用。在kubeflow中实现了Notebook CRD,可以快速部署notebook环境。
主要逻辑在 [notebook_controllers.go](https://github.com/kubeflow/kubeflow/blob/16ae921ff0c5b082a6366b4c9e47a04de10cf4ee/components/notebook-controller/controllers/notebook_controller.go#L89) 里。比较简单,创建Notebook CRD的时候,Controllers会创建StatefulSet、Service,如果有Istio的话,还会创建VirtualService。
模型训练 - TFJob
启动Pod和Service
主要在 [pkg/controller.v1/tensorflow/tfjob_controller.go](https://github.com/kubeflow/training-operator/blob/cf484c484fe0f54c5f06139455e0723965e9ac10/pkg/controller.v1/tensorflow/tfjob_controller.go#L156) 里。
这里调用了common的ReconcileJobs函数。ReconcileJobs是一个通用的函数,实现了所有Job的主逻辑,中间调用具体controller的实现来完成调谐Job。
ReconcileJobs函数的主逻辑
1 | // ReconcileJobs函数的主逻辑 |
训练集群配置的生成
主要在 [pkg/controller.v1/tensorflow/tensorflow.go](https://github.com/kubeflow/training-operator/blob/master/pkg/controller.v1/tensorflow/tensorflow.go) 里面
主要逻辑是拿到service地址和端口信息,最后塞到pod的环境变量TFCONFIG 里。
1 | // SetClusterSpec函数。生成集群配置,并塞到环境变量里 |
推理服务 - KServe
Kserve又是一个工具集,包含了很多组件,因此KubeFlow把它单独拎出来在更新。实际上也可以不依赖KubeFlow,单独部署KServe来实现推理服务。
下面是KServe的分层架构图,可以看到是在k8s上叠了一层Knative+Istio,然后再在上面叠了Kserve。KNative提供Serveless服务,Istio是服务网格,具体可以搜对应的文档。
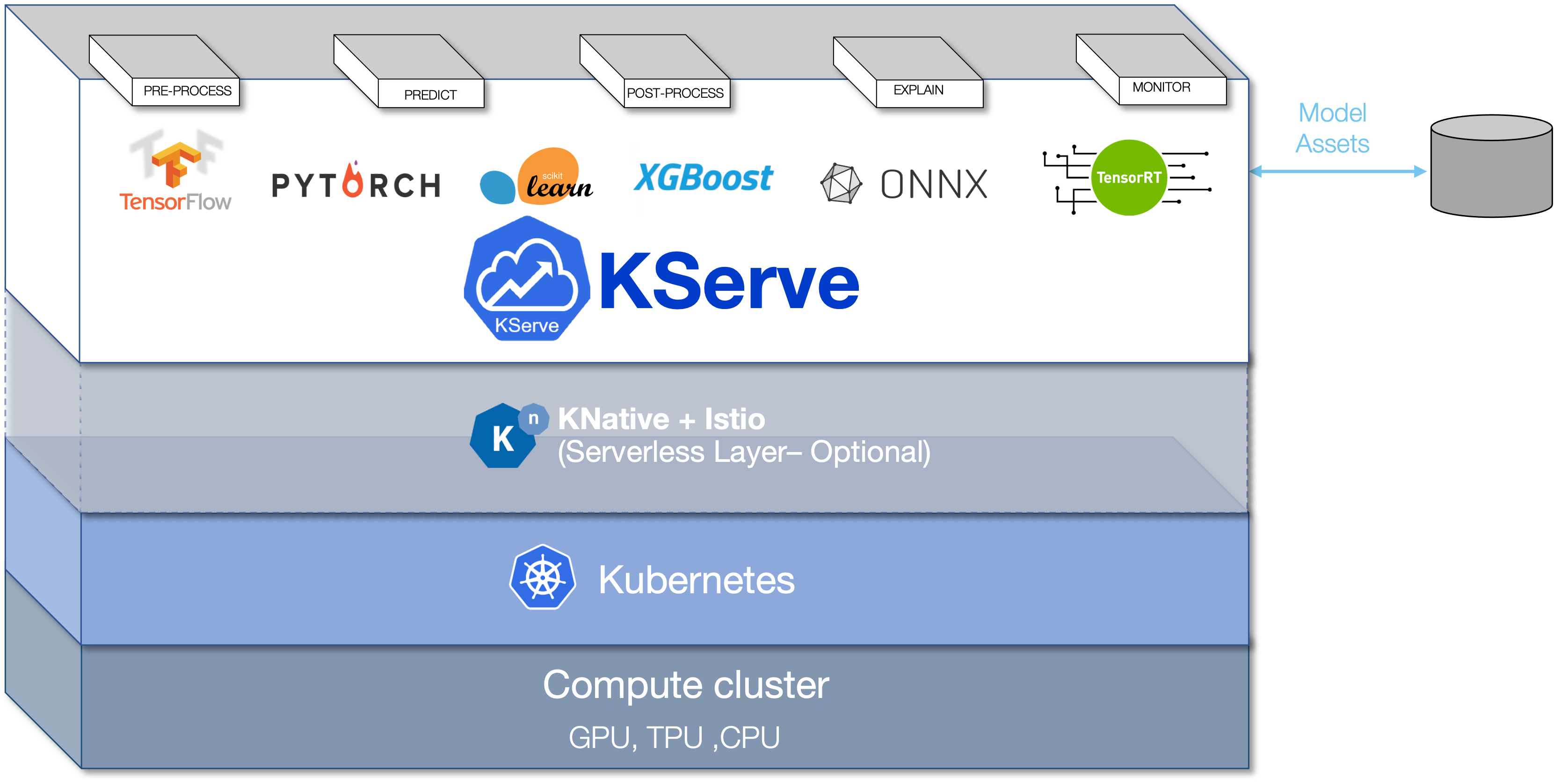
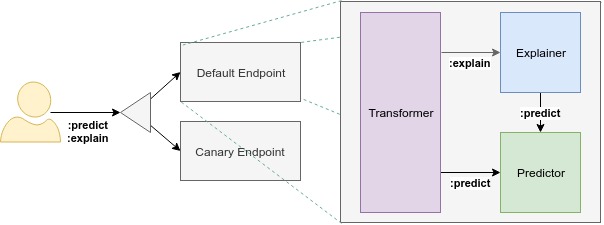
从用户的视角来看,KServe解决的是模型直接部署的问题,包含3个组件:
- Transformer:定义前处理和后处理步骤,格式转换等。可选。
- Predictor:真正的模型服务。必须。
- Explainer:解释模型的输出结果。可选。
具体代码就不再仔细看了。发现一个看代码的窍门,对于这类k8s之上的应用,都可以从Controller入手,找到 Reconcile 函数作为入口往下看就行了,基本上大同小异。
写在最后
KubeFlow有点胶水项目的意思,做的工作就是把各个机器学习组件通过Operator搬到k8s上。但是这个项目既然能存在,证明这个项目确实解决了实际的问题,产生了真实的价值。
我个人把它理解为“机器学习界的DevOps平台”(其实有个专有名词叫MLOps),它的主要价值是提升了机器学习模型从开发、测试到上线的工作效率,形成一套规范的工作流,并且因为是基于k8s环境的,所以这个工作流也可以在私有云、公有云之间迁移,只要有k8s环境即可。
如果你想要构建一个AI Infra平台,完全可以不用基于k8s自己开发,而是直接基于KubeFlow开始开发。KubeFlow项目已经覆盖了模型开发、训练、推理的一系列工具,不用重复造轮子,后续根据业务需求,专注于做好性能、稳定性、权限、计费等方面的工作,一个AI Infra平台就可以搭建起来了。