Airflow源码分析(4)-scheduler分析
scheduler的主循环
scheduler的逻辑:
- 遍历DAG路径下的所有dag文件
- 启动一定数量的进程(进程池),并且给每个进程指派一个dag文件。每个进程解析分配给它的dag文件,并根据解析结果在DB中创建DagRun和TaskInstance。对于满足执行条件的TaskInstance,将状态修改为SCHEDULED
- 在scheduler的主循环中,查询状态为SCHEDULED的TaskInstance,并将这个TI发送给executor异步执行。至于怎么执行scheduler就不管了,只需要从executor同步状态信息。
- 在进程池中如果有进程完成了,则创建新的进程处理下一个dag文件,并且保证这个进程池的进程数量不会超过配置的数量。
- 一旦所有的dag处理完毕后,就会进行下一轮循环处理。这里还有一个细节就是上一轮的某个dag的处理时间可能很长,导致到下一轮处理的时候这个dag还没有处理完成。Airflow的处理逻辑是在这一轮不为这个dag创建进程,这样不会阻塞进程去处理其余dag。
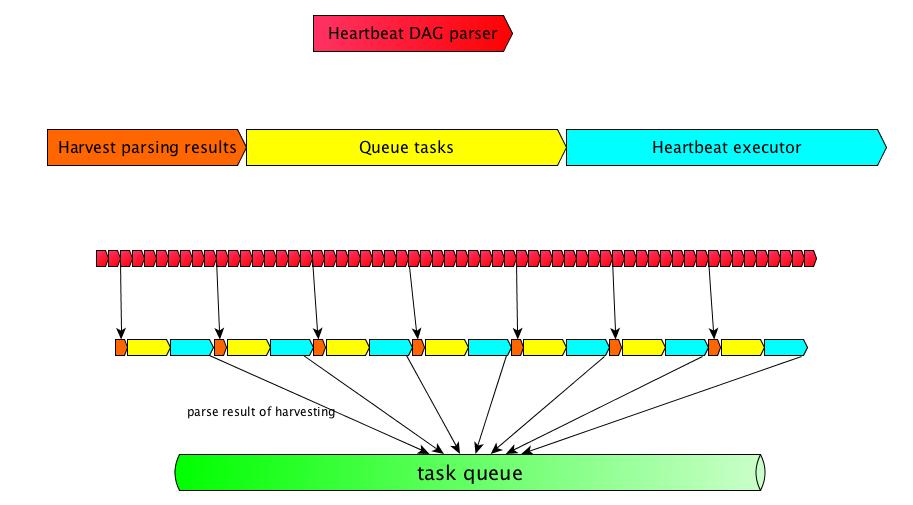
scheduler的主循环(_execute_helper):
- 收集从DagFileProcessorAgent得到的DAG解析结果
- 查找并且将可执行的task放入executor的队列
- 改变task instance在DB中的状态
- 将task加入到executor的队列中
- 发送心跳给executor
- executor在收到心跳后会异步执行队列中的task
- 同步task的状态
DagFileProcessorManager的主循环(start_in_async):
- 判断是否需要刷新当前的dag列表
- 从维护的进程池中取得DAG解析结果,并加入到result_queue中。result_queue中的数据会被agent在主循环中拿走
原文:
The actual scheduler loop. The main steps in the loop are:
- Harvest DAG parsing results through DagFileProcessorAgent
- Find and queue executable tasks
- Change task instance state in DB
- Queue tasks in executor
- Heartbeat executor
- Execute queued tasks in executor asynchronously
- Sync on the states of running tasks
The logic for scheduling is as follows:
- Enumerate the all the files in the DAG directory.
- Start a configurable number of processes and for each one, assign a DAG file to process.
In each child process, parse the DAG file, create the necessary DagRuns given the state of the DAG’s task instances, and for all the task instances that should run, create a TaskInstance (with theSCHEDULEDstate) in the ORM. - Back in the main scheduler process, query the ORM for task instances in the
SCHEDULEDstate. If any are found, send them to the executor and set the task instance state toQUEUED. - If any of the child processes have finished, create another process to work on the next file in the series, provided that the number of running processes is less than the configured limit.
- Once a process has been launched for all of the files in the DAG directory, the cycle is repeated. If the process to parse a particular DAG file is still running when the file’s turn comes up in the next cycle, a new process is not launched and a process for the next file in the series is launched instead. This way, a DAG file that takes a long time to parse does not necessarily block the processing of other DAGs.
代码结构
DagFileProcessor在子进程中解析DAG定义文件。对于发现的DAG,检查DagRun和TaskInstance的状态。如果有TaskInstance可以运行,将状态标记为SCHEDULED。
DagFileProcessorManager控制DagFileProcessors如何启动。它追踪哪些文件应该被处理并且确保一旦一个DagFileProcessor完成解析,下一个dag文件应该得到处理。并且控制DagFileProcessors的数量。
SchedulerJob通过agent获取manager的DAG定义文件解析结果,并且将SCHEDULED状态的TI发送给executor执行。
DagFileProcessorAgent作为一个采集代理,scheduler可以借助agent获取manager获取到的dag解析结果,并且可以控制manager的行为。
PS: DagFileProcessor中的process_file部分逻辑写在SchedulerJob中,当时也是让我对代码困惑的一点。
原文:
The DagFileProcessor launches a child process to parse a DAG definition file. For the DAGs found in the file, it examines DAG runs and the state of the task instances. If there are task instances that should run, it creates them in the SCHEDULED state.
The DagFileProcessorManager coordinates how DagFileProcessors are launched. It keeps track of which files need to be processed and ensures that once a DagFileProcessor is done, the next file in the series is processed accordingly. It also controls the number of simultaneous DagFileProcessors and ensures that the number if simultaneous instances do not exceed the configured limit.
The SchedulerJob coordinates parsing of the DAG definition files using the DagFileProcessorManager and sends task instances in the SCHEDULED state to the executor.
常见问题分析
- DAG是如何被解析的?哪个进程中实现?
- 在将py代码load_source时即被解析,对于每个task对象,保存有它的上下游task,后面统一进行Dep检测。
- Dep检测是一级一级串联的,除了上下游依赖关系,还有时间关系、多种触发规则的判断。
- DAG加载解析是在DagFileProcessor进程中完成的,同时也是在DagFileProcessor中标记哪些task是scheduled的状态,而在主进程中只需要查找得到这些状态的task即可。
- DagFileProcessor的作用?
- 解析特定的dag文件,调用process_file
- 根据dag文件创建合适的DagRun和TaskInstance
- 解析依赖关系将可以调度的TaskInstance标记为scheduled
SimpleDag和SimpleDagBag发挥了什么作用?
用于调度,保存有调度需要的字段而不包含执行需要的字段为什么scheduler需要agent的返回result_queue,不是直接在DB中查找scheduled的TaskInstance吗?
scheduler只调度simple_dagbag中的任务scheduler支持水平扩容吗?如何做到高可用?
不支持。但是可以高可用部署,一个scheduler挂了以后立即启动另一个scheduler。同时因为元数据保存在DB中,可以从DB中恢复。scheduler是如何解决可能调度同一DAG两次的问题的?
每个DAG分配一个进程,在DagFileProcessorManager中保存有dag和processor的映射表。在dag没有被任何processor处理的时候,才会给它创建新的处理进程。手动触发的DAG有何不同?
手动触发的DAG直接创建DR和TI,因此不需要经过DagFileProcessor创建。但是在创建以后,仍然是DagFileProcessor将TI的状态更改为SCHEDULED。
并发控制分析
1. DagFileProcessor的进程个数控制
配置项:max_threads
实现:在Manager的heartbeat()中会比较当前processor数和这个值
1 | # Start more processors if we have enough slots and files to process |
2. 同时运行的最大TaskInstance数量
配置项:parallelism
实现:在Executor的heartbeat()中会根据parallelism得出当前可用的slots数量,决定execute_async多少task
1 | # Triggering new jobs |
3. scheduler控制一次加入到queue中的TI个数
配置项:max_tis_per_query
实现:scheduler的主循环中找出那些ti可以被执行后,reduce_in_chunk时选的chunk_size就是这个值
1 | def _execute_task_instances(self, |
4. 扫描文件夹获取新的dag的时间间隔
配置项:dag_dir_list_interval
实现:在Manager的主循环(start_in_async)中每次循环都会调用_refresh_dag_dir()去判断是否满足刷新list_py_file_paths得到新加入的dag
1 | elapsed_time_since_refresh = (timezone.utcnow() - |
5. 控制DagFileProcessor解析DAG的速度
配置项:min_file_process_interval
在Manager的主循环的heartbeat()中会上一次解析完成时间到现在的时间间隔,如果小于min_file_process_interval,则跳过这个dag的解析
1 | now = timezone.utcnow() |
实现细节
很多地方用到了chunk_reduce,用来进行小的分批处理
1 | def chunks(items, chunk_size): |
dagbag在解析dag文件时,只会对最近修改过的文件进行解析
1 | file_last_changed_on_disk = datetime.fromtimestamp(os.path.getmtime(filepath)) |
总结
scheduler毫无疑问是整个Airflow的核心模块,逻辑复杂,从中可以一瞥典型scheduler的典型逻辑。
本文从scheduler的主要逻辑入手,分析了控制循环和代码结构,重点分析了物理实现上的并发控制和性能优化。
但是DAG的并发控制其实不止于此,还有同一Dag的DagRun并发执行数量控制、Dag的TaskInstance并发执行数量控制、TaskInstance运行在特定大小的Pool中进行数量控制。这些并发控制由Airflow的使用者在定义DAG时指定,在实现上是在scheduler的主循环中实现,也就是在将taskinstance加入到executor的队列前进行这些限制条件的判断。不满足条件的TI,即使是SCHEDULED的状态,也不会加入到executor的队列,也就不会变为QUEUED状态。这块的逻辑在SchedulerJob#_find_executable_task_instances方法中,就不展开讲了。
另外本部分代码也是Python多进程编程的一个典型案例,比如manager维护的进程池、agent与manager使用Pipe和Queue进行通信、scheduler借助agent维护manager的生命周期。