KServe中的优化技术
在上一篇KubeFlow的文章中已经介绍过KServe,KServer是一个用于在k8s上部署推理服务的框架。
这一篇更细节地分析KServe中的2项技术: ModelMesh和Batcher。
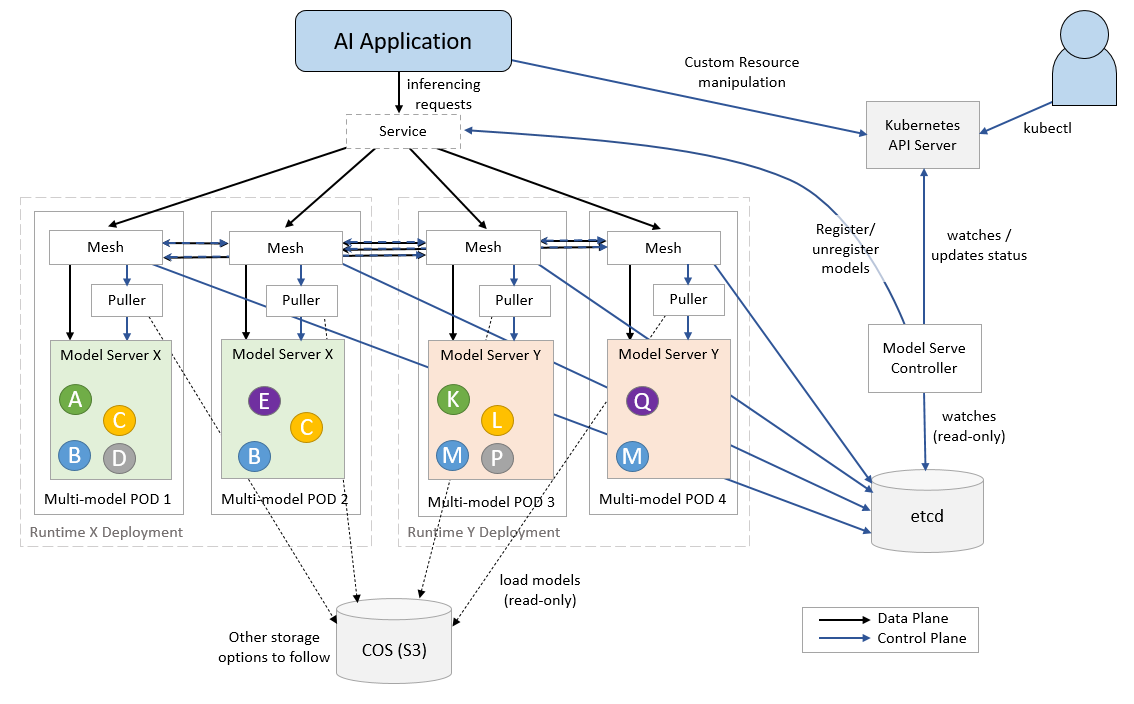
ModelMesh
KServe原本的InferenceService是一个模型一个服务的模式,在部署大量模型的情况下,会面临各种限制:计算资源的限制、POD数量的限制、IP地址数量的限制。
因此KServe开发了ModelMesh技术,一个pod可以加载多个模型,由mesh层来统一分发请求,提高资源利用率。其中Mesh层负责推理请求调度转发,Puller负责模型拉取。
个人认为这项技术就是借鉴的ServiceMesh的思想。比如在典型的ServiceMesh服务Istio中,通过VirtualService、DestinationRule来让用户以声明式方式控制服务之间的流量转发、路由、限流,而在实现中则以sidecar模式将proxy容器注入到服务容器中。
在ModelMesh中,则是通过ServingRuntime CRD部署了一组Deployment作为推理服务的运行时,具体实现上是以Mesh容器和Puller容器来处理流量转发路由以及模型的加载。
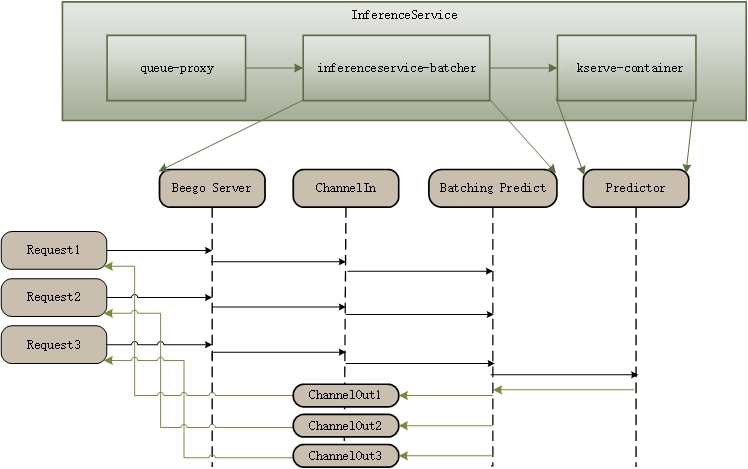
Inference Batcher
这个也很容易理解,GPU在处理批请求的时候资源利用率可以更高。
核心思想是将请求聚合,然后一次送入推理服务中,可以提高吞吐能力。
当请求数量batch size,或者间隔大于latency的时候发射。
代码在 pkg/batcher 里面
核心逻辑
1 | // handler.go:L179 |
输入输出
1 | type Request struct { |