记一次推理API性能优化
最近在DM的API上遇到了一些很有意思的性能问题,这里记录一下整个过程。
背景
在DM中,每一套API都是相互隔离的一套环境,使用不同的域名、不同的资源,但是代码复用,使用不同的模板+参数来满足不同的用户需求。下图是一套API的架构:
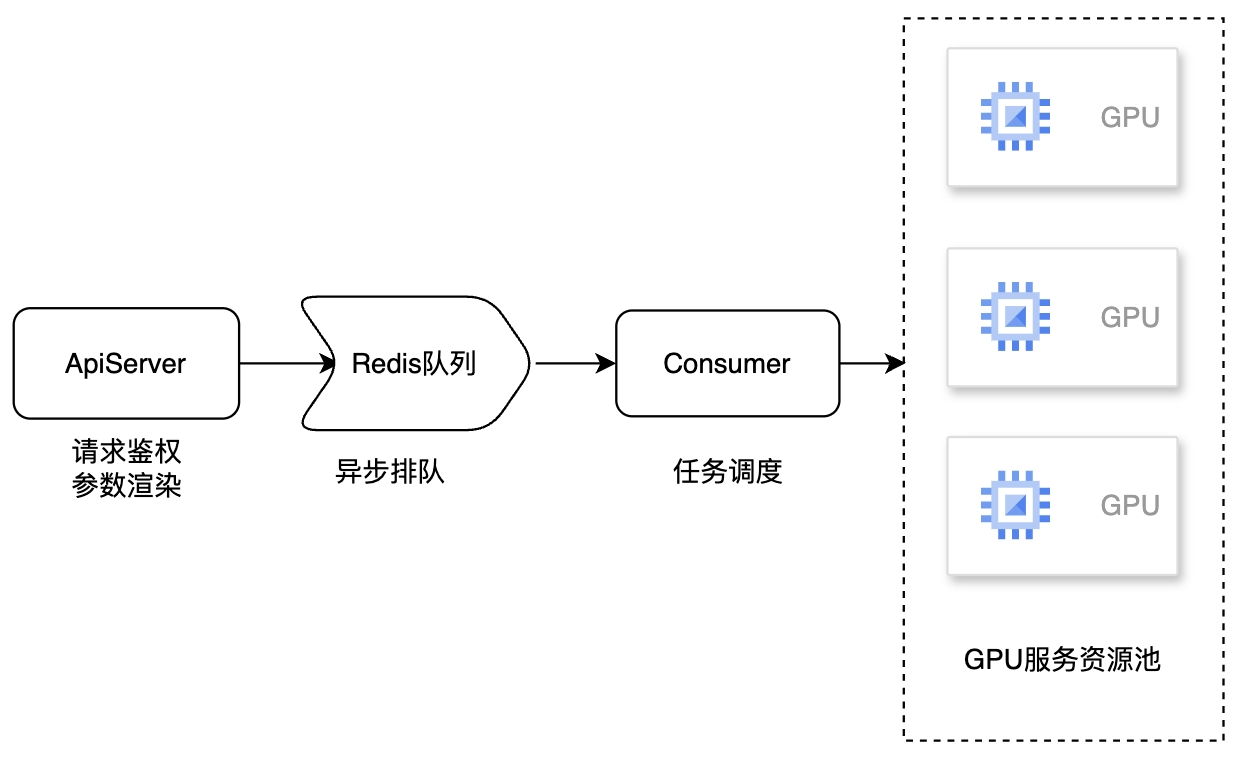
调用过程如下:
- 用户发起API请求,apiserver进行鉴权后,从配置中读取出出图模板,使用api请求的payload作为参数,渲染得到最终的出图参数,放入到Redis任务队列中,结束这一次请求
- consumer监听redis队列,从redis队列中读取出生图任务,在新的协程中同步调用GPU服务的推理API,并将结果写入到Redis结果队列中
- GPU推理API接收出图任务,绘图,并返回结果
- 用户使用task id轮询API接口,查询生图状态,最终得到生图结果
推理API中间链路优化
面临的第一个问题是GPU推理只需3s,而全链路需要18s,那么肯定是中间链路出现了问题。
中间链路主要是图片的上传/下载,以及任务的调度。看了一下日志,发现编解码的时间很长,需要10s以上,而且不稳定,一会快一会慢。
直觉是CPU出了问题,看了一眼CPU占用,发现宿主CPU占用100%,容器打满2个核。看了一下宿主上面跑了6个同样的容器,一共是12核,所以就是每个容器都在竞争,都分到2个核。
CPU过载
先review了一遍调度的代码,很快发现for循环中没有sleep。
1 | for { |
如果是单核死循环,那最多也就用到1核,但是代码里开了10个协程,所以最高会打满10核。
另外又想了一下,这版已经是被优化过后的版本了,但是之前的服务CPU占用也很高。这是为什么?
看了一下代码,发现前面还是死循环。 for-select的形式不能写default
1 | func UntilWithContextMulti(ctx context.Context, f func(context.Context, string), period time.Duration, key string) { |
其实IDE会报Warning。通过静态代码扫描很容易发现这种问题。

最终在for循环中加了一个sleep就解决了。
无意义的编解码
但是此时发现编解码还非常耗时,又review了代码,发现原来存在无意义的image.decode/image.encode。
1 | // buf 和 data 是一样的 |
结果
经过去掉死循环+去掉无意义的编解码后,成功将出图时长从18s降到了4s内,效果显著,而且CPU不会被打爆了。
单卡多服务节省成本
业务需要2个API:检测API 和 出图API
最简单的方式当然是部署2个服务,但是这样需要更多的卡。但是检测API的模型其实很小,速度也很快,那么能不能将这2个服务部署到一张卡上呢?
本地排队支持
在开始2个服务部署到一张卡上之前,我们需要先解决一下API在并发的情况下会报错的问题。
因为GPU的特殊性,同一个进程中只能有一个推理任务在跑,但是uvicorn接受请求是多线程的,并发请求推理服务会报错。那么需要实现本地排队机制。
方案0: 队列
这个最容易想到,在endpoint中,接收到请求后,丢到一个queue中,另一端有个线程读取任务并执行。但是这样存在一个问题,任务执行的result怎么拿到?
另外再开一个result队列?好麻烦啊。
方案1: 单线程的线程池
GPT老师给了个更巧妙的方案,使用1个线程的线程池。
这样既用到了threadpool中的work_queue,又通过python的future句柄拿到结果,3行代码搞定。
1 | with ThreadPoolExecutor(max_workers=1) as executor: |
方案2: 锁,但是FIFO
后来看了一眼webui的实现,发现它是用锁实现的,而且还实现了FIFO的锁,挺有意思的。
代码如下,中间关键点是用到了 threading.Event 。
在Python中,threading.Event 是线程同步的一种机制。它有一个内部标志,可以由线程设置或清除。其他线程可以等待这个标志被设置。一旦这个标志被设置,所有等待它的线程将被唤醒。
步骤如下:
- 在获取锁时,实际上是将event加入了queue中,然后自己wait
- 在释放锁的时候,从queue中取出第1个元素,然后
release_event.set()。这样在等待的线程就会被唤醒,实现了FIFO的锁。
1 | import threading |
单卡多服务实现
尝试单进程排队
最开始想到的是uvicorn启动,使用2个不同的endpoint。
1 | app = FastAPI() |
但是这样会有问题:检测接口和出图接口会相互排队,浪费了资源。
多进程实现
虽然单进程只能有一个服务在跑GPU,但是多进程是可以同时使用GPU的。
所以干脆拆成2个服务,分别监听不同的端口,在启动脚本中启动这2个进程,并waitpid,只要有1个进程挂掉就整体挂掉,让容器重启。
最终实现如下:
api_image.py
1 | app = FastAPI() |
api_detect.py
1 | app = FastAPI() |
run.sh
1 |
|
MPS
其实Nvidia还有另一种技术叫MPS,可以将一张物理卡虚拟化为多张卡。不过这时候再去开启MPS收益也较小了。感兴趣的同学可以看下:https://docs.nvidia.com/deploy/mps/index.html
结果
经过上面的操作,GPU显存使用率可以达到90%,充分利用了GPU资源,不会给业务额外的成本。
2个API服务不会相互排队,用最小的成本实现了单卡多服务,虽然比单卡单服务速度慢几百毫秒,但是可以接受。
奇怪的推理性能问题排查
又碰到一个奇怪的问题,同样的模型,在IDC的机器上跑需要35s,在阿里云上需要45s,这是为什么?
镜像、驱动、硬件问题?
- 镜像问题?重新打包了几遍镜像,确认了一遍模型的hash值。没用。
- 驱动问题?升级了一波机器的驱动,跟IDC的对齐。没用。
- 硬件问题?跟阿里云的人联系了一下,他们直接在机器上能跑出10s的速度,非常奇怪。
居然又是CPU的问题
最终尝试换个镜像,新镜像需要编译模型,比较耗内存,所以我干脆去掉了pod limit。这时候再跑发现速度很快,但是我发现不论是新镜像还是旧镜像都很快,那么唯一的不同就是pod limit了。因此终于发现又是CPU的问题。
阿里云的cpu限制了7核,IDC的cpu限制了11核,所以IDC的机器跑得快一点。如果完全把CPU limit放开,出图时长可以从45s降到9s。
感悟
这个问题断断续续困扰了我1周多,很烦。
其实如果是CPU服务,那跑得慢我第一时间就会想到去看一眼CPU利用率,但是对GPU服务陷入了误区,一直在纠结镜像、驱动、硬件,而没有想到去看一眼CPU利用率。甚至有同学一开始提到了CPU限制,但被忽略了。
另一个暴露的问题是基础设施不完善,如果有CPU利用率报警,无论是前面的死循环问题,还是这个CPU limit问题都很容易被发现和解决。
模型预热和切换优化
模型预热
模型第一次加载需要很长的时间,最好的方式就是在节点注册前就完成模型预热,预热最快的方式就是出一张图。
对于webui来说,本身有一些callback,可以在on_app_started注册回调,完成模型预热的功能。
1 | import modules.script_callbacks as script_callbacks |
但是在我们的场景下,需要等到API就绪后才能预热,所以需要在轮询API端口监听后才预热。
1 | def do(): |
模型池化
最后一个需求是业务需要多个模型的出图,但是又不想在节点上切模型,因为切模型需要耗费几十秒。因此需要维护模型池,每个节点只加载1个模型,由scheduler将任务调度到加载了对应模型的节点上。
方案1:划分队列
最暴力的方式是起多套scheduler+gpu服务,在apiserver根据任务转发到不同队列。麻烦的地方在于需要大量配置,运维工作量大。
方案2:模型池
这种方式是在代码层面上实现模型池,在调度器中实现动态分配模型,且只在注册时切换一次模型,实现“软性的模型池”。
- 当节点注册时,调度器根据当前的模型加载情况,尽量保持均衡,分配一个模型给这个节点,调用节点的切模型接口和预热接口,然后将这个节点加入到模型池中。之后不再切换模型。
- 在收到任务时,根据任务中的模型,将任务调度到对应模型池中的节点上。
但是这样存在问题,比如调度器重启后模型池信息就丢失了,而持久化存储的话节点信息可能不同步,边界条件较多。
方案3:模型池,但是调度
- 节点依然使用不同的模型启动,并打上label标记自身的模型,注册时上报自身模型
- 调度器接受上报的节点信息,在内存中维护模型池信息
- 在收到任务时,根据任务中的模型,将任务调度到对应模型池中的节点上。
最终使用的方案三,开发成本和运维成本都低。
总结
以上就是最近项目上碰到的一些问题的总结,从API中间链路优化,到单卡多服务节省成本,再到奇怪的性能问题排查,最后是模型预热和切换优化,总结下来似乎是一个踩坑然后填坑的过程。